Jesienią tego roku odbędą się wybory parlamentarne i po raz kolejny internet będzie jedną z ważnych scen, na której politycy będą chcieli pozyskać poparcie. W latach 90. politycy - także polscy - interesowali się Webem, chociaż jego społeczne oddziaływanie było radykalnie mniejsze niż dziś. Ten wątek rozwinę na blogu pewnie jesienią - dziś wolałbym odnieść się do wyborów parlamentarnych z 1997 roku w inny sposób. Przeglądając korpus artykułów z Wyborczej (1996-2001) znalazłem tekst, który - w kontekście kampanii wyborczej i głosowania, opowiadał o czymś bardziej fundamentalnym. Oto treści online jest coraz więcej - jak do nich dotrzeć?
W Webie lat 90. wyszukiwanie informacji było przede wszystkim wyszukiwaniem stron. Popularne wówczas katalogi, rozwijane w ramach portali, albo jako osobne społecznościowe projekty (DMOZ, zał. 1998), gromadziły i opisywały odnośniki, ale nie były w stanie katalogować zawartej pod nimi wiedzy. Nie było wtedy jeszcze Wikipedii (zał. 2001), która dziś jest wolnym źródłem wiedzy pozwalającym na zaawansowane maszynowe kwerendy, dzięki czemu Google może uwzględniać je w generowaniu “paneli wiedzy”, a ChatGPT w przewidywaniu odpowiedzi na pytania zadane przez użytkownika. Informacja i wiedza przestały mieć URL, chociaż istnieje podejście, które to zmienia.
Korzystanie z katalogów takich jak DMOZ czy katalogów na portalach Onetu i WP nie było najefektywniejszym sposobem docierania do informacji, ponieważ wymagało pewnych wstępnych kompetencji: trzeba było przypisać poszukiwaną informację do jakiejś kategorii (np. skutecznie założyć, że dane o populacji Gdańska znajdziemy w kategorii “Miasta” a nie w kategorii “Nauka” albo “Instytucje państwowe”). Po drugie, opisy stron w danej kategorii nie musiały specjalnie pomagać w dokonaniu wyboru - trzeba było odwiedzić każdy URL i samodzielnie sprawdzić, czy na stronie znajdują się poszukiwane informacje.
Nieco inaczej działały webringi - kolekcje połączonych ze sobą (zazwyczaj tematycznie) witryn, z których każda promowała inne witryny ze zbioru za pomocą niewielkiego widżetu. Tutaj strony mogły gwarantować sobie wzajemną jakość, a użytkownik swobodnie mógł przechodzić od jednej do drugiej bez znajomości adresów URL.
“Strony powstają jak grzyby po deszczu”
W 1997 użytkownicy Webu mogli korzystać z wielu wyszukiwarek. Oczywiście nie było wśród nich wyszukiwarki Google (firma została założon dopiero rok później), która dominację zdobyła już w XXI wieku: w badaniach Megapanel PBI/Gemius notowana była na pierwszym miejscu listy najpopularniejszy stron w Polsce dopiero w 2006 roku. Wyszukiwarka, budowana automatycznie przez czytające treści stron roboty, pozwalała użytkownikom ignorować adresy URL - po prostu wskazywała je na podstawie określonych zapytań, a użytkownik mógł kliknąć lub nie w proponowane linki.
Różnica między katalogiem WWW a wyszukiwarką polegała głównie na tym, że katalogi kategoryzowały i opisywały strony i całe witryny, na których mogła znaleźć się jakaś informacja, a wyszukiwarki - dzięki temu, że mogły brać pod uwagę pełną treść, operowały na poziomie informacji (słowa kluczowego, paragrafu itp.). Co nie mniej ważne, ponieważ ich zasoby były gromadzone automatycznie, mogły szybciej aktualizować informacje o stronach. Jak czytamy w artykule Jarosława Zielińskiego z września 1997 roku:
Jeśli chcemy zapoznać się z informacjami dotyczącymi polityki i kampanii wyborczej w nadchodzącym gorącym przedwyborczym okresie, to czeka nas trudne zadanie. Strony internetowe zajmujące się polityką i wyborami powstają jak grzyby po deszczu i nie ma jednej osoby czy jednego spisu stron internetowych, które mogłyby wskazać nam wszystkie. Pewnym wyjściem są usługi wyszukiwawcze (“Wybory w Internecie / Poszukiwania politycznych informacji”).
Cytowany przeze mnie artykuł informuje o uruchomieniu przez ICM UW polskiej wersji wyszukiwarki Infoseek.
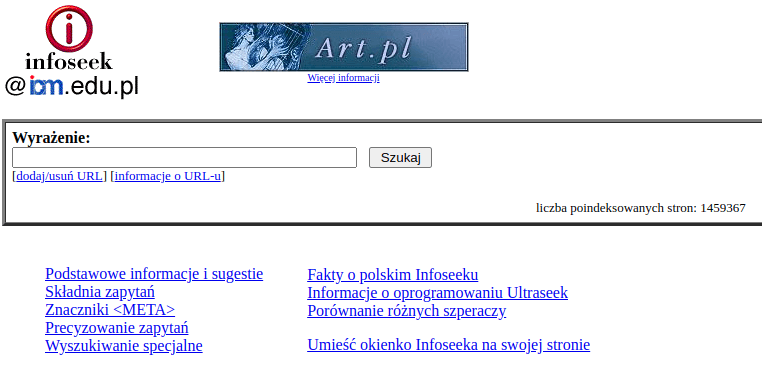
Wpisane pytanie jest wysyłane do programu wyszukującego (search engine), ten zagląda do zgromadzonego wcześniej przez swojego “poszukiwacza” (spider, indexing robot) indeksu zawartości stron i wyjmuje stamtąd opisy tych dokumentów, które odpowiadają zadanemu pytaniu. Każdy opis zawiera odnośnik do strony i kilka pierwszych zdań z treści. W końcu program wyświetla opisy na ekranie przeglądarki. Jak zadać pytanie? Teraz czas na pytanie. Jeśli podamy tylko słowo “wybory”, otrzymamy ponad kilka tysięcy odpowiedzi. Słowo to wystąpiło na 3600 stronach internetowych; część z nich dotyczy wyborów parlamentarnych, inne wyborów władz uczelni albo Miss Polski. Można ten zalew informacji nieco ograniczyć, podając wyrażenie, na przykład “wybory parlamentarne”. Liczba dokumentów spełniających te kryteria spada do nieco ponad 200. Ale może to już zbyt szczegółowe pytanie? Spróbujmy inne: “wybory do Sejmu”. Otrzymamy prawie 80 dokumentów, nieco innych niż w poprzednim pytaniu. Można tak przetestować sposób działania innych wyrażeń, które nam przyjdą do głowy; im dłuższe, tym lepsze, bo dające w odpowiedzi mniej dokumentów, ściślej związanych z tematem. Innym sposobem jest wskazanie kilku wyrazów, które mają znaleźć się jednocześnie na tej samej stronie, na przykład “+wybory +1997”. Plus oznacza, że słowo musi się pojawić. Otrzymamy ponad 400 dokumentów. Na kolejne podejście pozwala nam specjalny operator wyszukiwania w Infoseeku - “site”. Dzięki niemu można ograniczyć poszukiwania tylko do dokumentów znajdujących się na konkretnym serwerze. Tak więc pytanie “wybory +site:www.wybory97.pl” da nam w odpowiedzi około 150 dokumentów serwisu “Wybory.97.pl”, a pytanie “wybory -site:www.wybory97.pl” - dokumenty o wyborach poza tym serwisem (“Wybory w Internecie / Poszukiwania politycznych informacji”)
“Polski” Infoseek na serwerach ICM-u miał być efektywniejszy od innych wyszukiwarek, gromadzących też informacje o polskich stronach:
Inne usługi wyszukiwawcze w Polsce to Netoskop na serwerze pisma Chip, wyszukiwanie w OptimusNet i w Wirtualnej Polsce. Warto wspomnieć również o światowych “szperaczach”, największym HotBot i bardzo znanej w Polsce AltaViście.
“Kod napisała krajowa firma”
W grudniu 1996 roku portal Polska OnLine udostępnił wyszukiwarkę Sieciowid, jednak w wyniku sporu z jej twórcą Michałem Rolskim, zmieniono oprogramowanie na zagraniczne (wyszukiwarka miała przez to problemy z wyświetlaniem polskich znaków), a Rolski sprzedał swój projekt wydawnictwu Vogel. Wydawany przez nie miesięcznik Chip udostępnił ją później na swojej witrynie. Jak pisał w lutym 1997 roku Przemysław Gamdzyk,
Netoskop od samego początku tworzony był z myślą o katalogowaniu zawartości polskiego Internetu. Miał on być wyłączną własnością firmy NetWalker, jednak brak odpowiednich środków finansowych zmusił jego autorów do poszukiwania partnera, z którym wspólnie można by uruchomić serwis wyszukiwawczy. Rozmowy prowadzone z kilkoma najważniejszymi firmami komputerowymi i operatorami Internetu skończyły się niepowodzeniem. Obecnie Netoskop funkcjonuje jako fragment internetowego serwera miesięcznika Chip. Jest to jedyny serwis wyszukiwawczy w polskiej sieci, którego kod napisała krajowa firma. Obecnie w bazie skatalogowanych jest sto kilkadziesiąt tysięcy stron WWW. Sieciowid zaczął działać prawie jednocześnie z Netoskopem. Niestety, oba serwisy nie potrafią eliminować powtórzeń stron w generowanych odpowiedziach (“Szukajcie, a znajdziecie”).
Bez wątpienia wzrost dostępności i znaczenia wyszukiwarek WWW pokazywał rozwój Webu - także polskojęzycznego. W kontekście wyborów 1997 roku miały one znaczną przewagę nad katalogami:
Katalogi mają opóźnienia nieraz kilkutygodniowe w dodawaniu nowych stron, a do wyborów zostało nam już mało czasu. Oprogramowanie Infoseek sprawdza Internet co najmniej dwa razy w tygodniu, a podana mu nowa strona czasem jeszcze tego samego dnia znajdzie się w indeksie (“Wybory w Internecie / Poszukiwania politycznych informacji”)
Web robił się coraz bardziej aktualny, szybciej reagował na wydarzenia, szybciej przejmował nowe informacje. Bez pośrednictwa maszyny użytkownik nie był w stanie nadążyć za tymi aktualizacjami.




